

Today, we are fortunate to present to you an article by Baptiste Meunier (ECB).timeThe views expressed in this article are those of the authors and not necessarily those of the institution to which they are affiliated.
In a recent NBER working paper (Chinn, Meunier, and Stumpner, 2023),and Sebastian Stampner (Bank of France) and Menzie Chinn (University of Washington), we now use machine learning methods to predict world trade. The reason for instant forecasting of global trade is simple: official statistics are released with a certain delay (two months), while multiple early indicators are available. The use of machine learning techniques responds to the high volatility of trade growth to a far greater degree than other macroeconomic variables such as GDP or employment. The idea is that the accuracy of predictions can be improved using non-linear techniques, the best example being machine learning. This post details two important lessons drawn from our paper that may be useful to other forecasters.
Lesson 1: Among nonlinear models, linear regression based machine learning techniques seem to perform better – although they have been much less reported in the literature so far
While we tested a range of different machine learning techniques, an important part of our research was based on the differences between these techniques Tree and those based on return.The first category includes random forests and gradient boosting, by aggregating multiple decision tree Together. It is the most widely used in the literature, especially Random Forest which has become popular in recent years.The second class is an adaptation of the first class, but using linear regression replace or supplement decision tree.It includes macroeconomic random forests (Goulet-Coulombe, 2020) and gradient linear boosting, these two innovative approaches have received much less attention in the literature so far.
However, based on machine learning techniques return It significantly and consistently outperforms other techniques across different horizons, real-time datasets, and economic conditions.they performed well TreeBased on methods – despite their growing popularity in the literature – underperformed in our setting. This supports recent evidence that such techniques may not be suitable for dealing with short samples of time series in macroeconomics.Comparing more extensively, we find that returnMachine learning-based techniques also significantly and consistently outperform more “traditional” techniques, whether linear (OLS) or nonlinear (Markov switching, quantile regression).
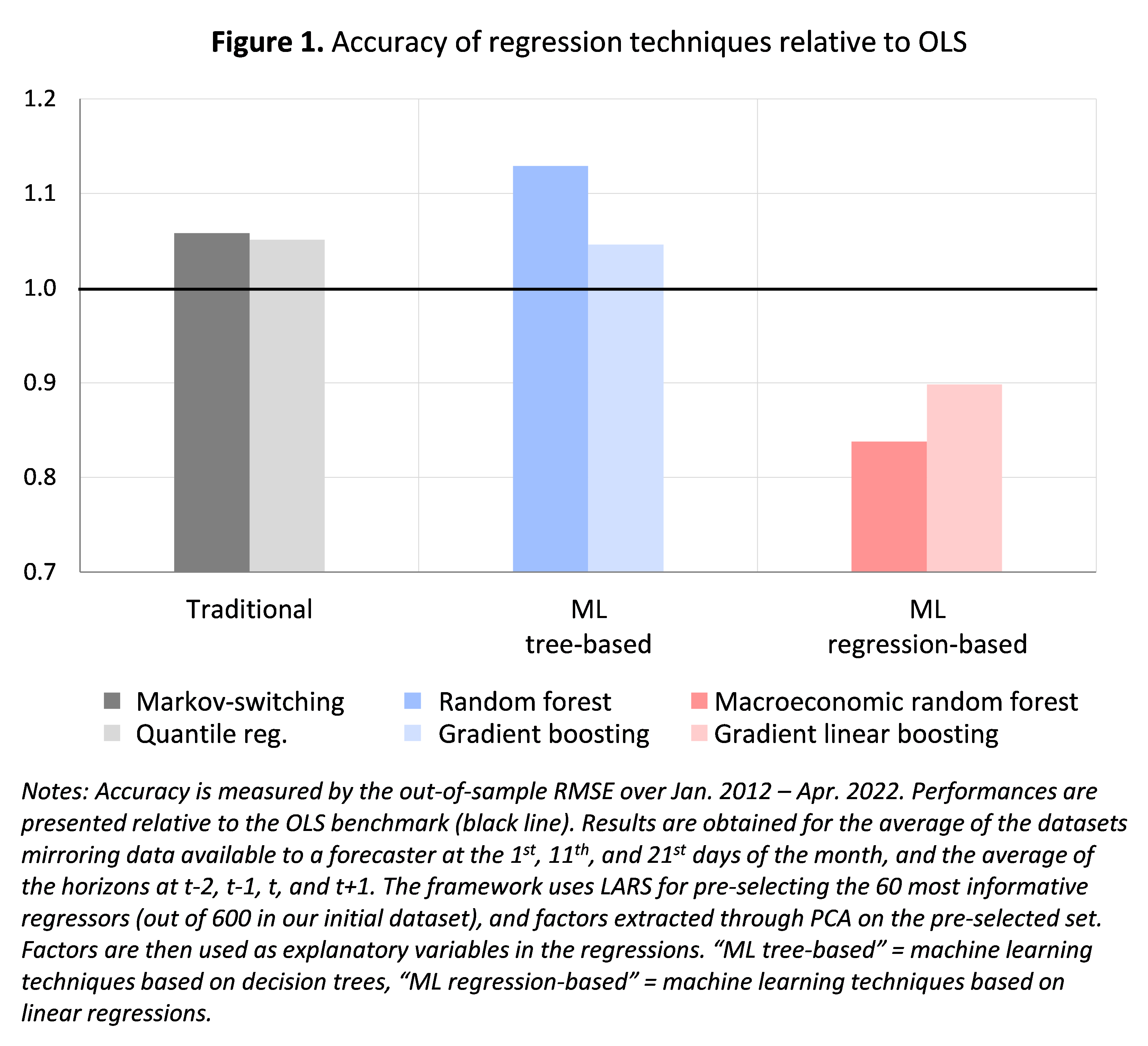
Personally, the best performing method is Goulet-Coulombe (2020)’s Macroeconomic Random Forest, which is an extension of the classic Random Forest.This can be found at figure 1 It represents the accuracy (measured by out-of-sample RMSFE for 2012-2022) of the different techniques relative to OLS (= 1, represented by the black line). “Traditional” non-linear techniques (shades of grey) and based on Tree (shaded in blue) fails to improve the OLS benchmark, and is even slightly less accurate (indicated by RMSE higher than the black line).Machine learning techniques based on linear regression In contrast, (shaded red) outperforms the OLS benchmark by an average of 15-20%, and thus outperforms other nonlinear techniques as well. Among these techniques, the best technique is macroeconomic random forest (dark red).Exceeds the results presented in figure 1averaged over different ranges and real-time datasets, the evidence in our paper shows that these results hold across different ranges, real-time datasets and economic states.
Lesson 2: Pre-selection and factor extraction of input datasets appears to improve the accuracy of machine learning-based predictions
To maximize the accuracy of machine learning-based predictions, our paper proposes a three-step approach consisting of (step 1) Preselection, (step 2) factor extraction, and (step 3) Machine learning regression. It is motivated by the literature: for example, Goulet-Coulombe et al. (2022) showed that machine learning techniques are more accurate when used in factor models. Preselection in factor models is a response to another literature (Bai and Ng, 2008) that found that selecting fewer but more informative regressors improves the performance of such models. Our framework combines these two aspects and applies them to a range of machine learning techniques.
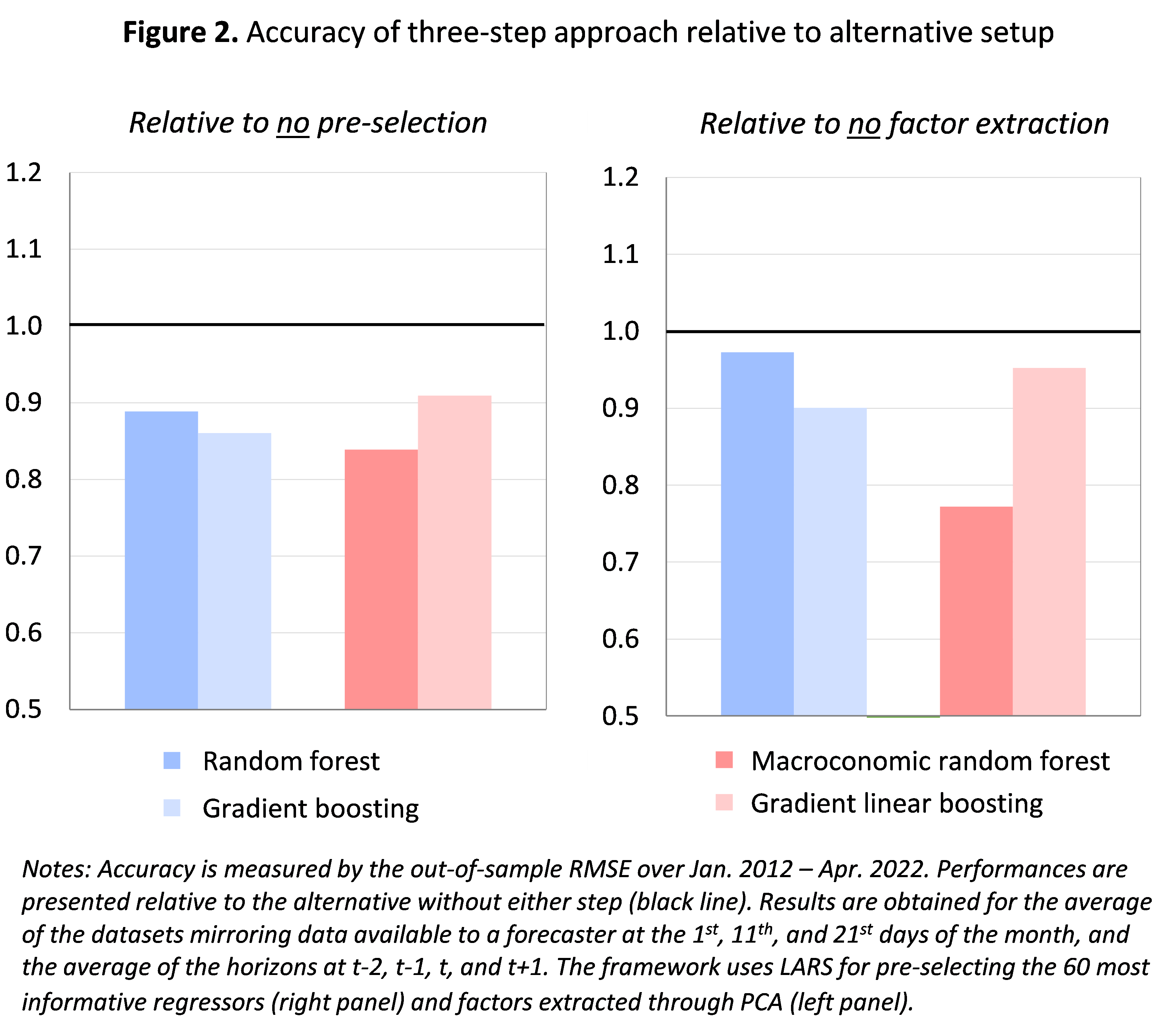
Both pre-selection and factor extraction improve the accuracy of machine learning-based predictions. In our setup, adding preselection improves prediction accuracy by about 10-15% on average. Preselection is therefore also useful for machine learning techniques, although it is generally believed that such techniques are designed to handle large datasets of uncorrelated variables. Also, using factors provides more accurate predictions than using all individual variables as regressors, with an average improvement of around 10-15%.This shows up in figure 2 It demonstrates the accuracy of the three-step approach relative to alternative settings where we skip the pre-selection step (left panel) or the factor extraction step (right panel). In both cases, the three-step approach (represented by the colored bars corresponding to the different machine learning techniques) outperforms the alternative (black line at 1) in accuracy.Average the results again figure 2but the classification results (provided in the paper) lead to similar conclusions.
Finally, the three-step approach significantly outperforms other workhorse nowcasting techniques in our setting.It first outperforms the widely used “diffusion index” method of Stock and Watson (2002), which uses two steps: factor extraction pass Principal component analysis (PCA) and OLS regression of these factors. Compared to this approach, the three-step approach can be viewed as an extension of preselection and machine learning. Our method also outperforms dynamic factor models, a technique widely used in the nowcasting literature. Finally, we also tested a range of preselection and factor extraction methods and found that in our setting the best combination was given by Least Angle Regression (LARS; Efron et al., 2004) for preselection and PCA . for factor extraction.
In short, our own experience using machine learning for nowcasting provides two important lessons that are best summed up in the three-step approach we propose. The framework can also provide a practical step-by-step approach for forecasters willing to use (or at least test) machine learning methods on their favorite datasets.To make this easier, we’ve shared a simplified version of the code at GitHub.
refer to
Bai, J. and Ng, S. (2008). “Forecasting Economic Time Series Using Objective Predictors”, Journal of Econometrics146(2), pp. 304–317
Chinn, MD, Meunier, B., Stumpner, S. (2023). “Forecasting World Trade Using Machine Learning: A Three-Step Approach”, NBER working paperNo 31419, National Bureau of Economic Research [ungated version]
Efron, B., Hastie, T., Johnstone, I., and Tibshirani, R. (2004). “Minimum Angle Regression”, Statistical Yearbook32(2), pp. 407–499
Goulet-Courlon, P. (2020). “Macroeconomics as Random Forests”, arXiv preprint
Goulet-Coulombe, P., Leroux, M., Stevanovic, D., and Surprenant, S. (2022). “How can machine learning help macroeconomic forecasting?”, Journal of Applied Econometrics37(5), pp. 920–964
Stock, J. and Watson, M. (2002). “Forecasting using principal components of a large number of predictor variables”, Journal of the American Statistical Association97(460), pp. 1167–1179.
The author of this article is Baptiste Meunier.


{kind=link}
{kind=link}