

What should you do when you want to perform a cost-benefit analysis based on efficacy estimates from a clinical trial but the trial lacks data. A common approach—called a complete case analysis (CCA)—is to discard participants whose observations are incomplete. This approach is problematic because not only will the estimator be less efficient (due to the small sample size), but the estimate can also be biased if the missing data does not appear randomly.Common approaches to this problem include multiple imputation (MI) (see Lellent et al. 2018) or Bayesian methods (see Gabrio et al. 2019) and a linear mixed model (LMM).In this article, we provide an overview of the LMM approach, mainly from Gabrio et al. (2022) Paper.
Consider the following regression structure:
In this equation, the term Yesij results of interest A generation and at different points in time j. has a series of phosphorus predictor Xi1,…,Xintellectual property with the corresponding coefficient β1,…, ΒP+1. The conventional error term is εij and the term ωA generation is the random intercept. This equation treats the data as having a 2-level structure, where σ2ω and σ2e Response variance between (level 1) and (level 2) individuals is captured, respectively.
The paper also describes an LMM, which is a repeated measures mixed model. Consider the case where we modeled patient estimates of quality of life data (ie, utility) that were collected 3 times during the trial (ie, baseline and 2 follow-up visits). We can mathematically write this model as:
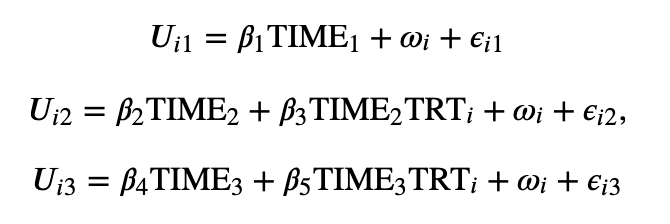
In this equation, we see that utilities have a fixed measure of whether utilities were collected at baseline, at the first visit, or at the second visit. After the baseline estimation, the follow-up equations also included the interaction term between treatment and time to collect utility. Note that by using a random effects term, we are able to account for the between-individual and between-individual variability in utility; if there is significant heterogeneity in utility between individuals, there is little change relative to the between-individual baseline utility level situation, any missing data will increase the uncertainty of the estimate. When data are missing, the utility or QALY effect can still be estimated from a weighted linear combination of the coefficient estimates for this utility model.
The authors note that a key limitation of the LMM is that it requires observation of all covariates at baseline. While this may be a common situation, the authors argue that “in RCTs, missing baseline data can often be addressed by implementing a single imputation technique (e.g., mean imputation) to obtain complete data before fitting the model. , without losing effectiveness or efficiency.”
Gabrio and co-authors also released their Stata and R code on GitHub (see here).


{kind=link}