

Today, we are pleased to present the contribution of our guest Laurent Ferrara (Professor of Economics, Skema Business School, Paris, international association of forecasters).
The recent series of economic, financial and pandemic crises around the world have sharply shortened the horizons of macroeconomic forecasters. At the heart of the Covid-19 crisis, the time frame of interest is this weekend rather than two years ago. This leads practitioners to focus on new types of high-frequency and alternative datasets, which pose new challenges for econometricians (unstructured data, very large datasets, mixed frequencies, high volatility, short samples…).
Various alternative data sources have been used in recent literature, such as web scraped data, scanner data or satellite data.Typically, these datasets are very large and can be considered as Big Data. One of the main sources of alternative data is Google search data, and the seminal paper on using such data to make predictions is that of Hal Varian and co-authors (see example here). In the field of nowcasting/forecasting, the literature tends to demonstrate that Google data has some predictive power, at least for some specific macroeconomic variables such as the unemployment rate (D’amuri and Marcucci, 2017) employment (Borup and Montes Schutte, 2020), building permit (Coble and Pincheira, 2017) or car sales (Nymand and Pantelidis, 2018). However, the jury is still out on what economists can gain from using Google data for forecasting and nowcasting when properly compared to other sources of information. A much-debated side question on Econbrowser concerns the reproducibility of these data by practitioners (see here Discussion between Hal Varian and Simon van Norden).
In a recently published paper, Ana Simeone inside Journal of Business and Economic Statistics (see here Emoticons), we asked ourselves whether the Google data could still be used to forecast quarterly GDP growth when controlling for official variables such as opinion polls or manufacturing production that forecasters typically use. If so, when exactly did these alternative data increase the accuracy of nowcasting. Imminent GDP growth is extremely useful for policymakers to assess macroeconomic conditions in real time.The concept of macroeconomic forecasting has become popular Giannone et al. [2008] And differs from standard forecasting methods in that it aims at high-frequency assessment of current macroeconomic conditions. The idea is to provide policymakers with a real-time assessment of the state of the economy ahead of the release of the official quarterly national accounts, which are always delayed.see example here to the U.S. economy and here A recent article published on Econbrowser.
Because the Google search data is high-dimensional, that is, the number of variables is larger than the time-series dimension, there is a cost to using them: first, we need to reduce their dimensionality from super high to high by using a filter procedure, and second , we need to use a regularized estimator to handle the preselected variables.A regularization technique is a method of interpreting many potentially correlated variables as a linear regression (see example Ridge estimate). In this regard, we propose a novel method combining variable preselection and ridge regularization, capable of explaining large databases.In this paper, we provide some theoretical results on the nice asymptotic properties of this estimation strategy, which we call Ridge after selection.
In addition to these theoretical results, we obtain a set of empirical results that may be interesting to share with those interested in macroeconomic forecasting using high-dimensional surrogate data. Our objective is to forecast quarterly weekly GDP growth for the US, the Eurozone and Germany over 3 economic periods: (i) a calm period (2014-16), (ii) a sudden downturn in GDP growth (2017-18, related to the trade war between the US and China/Europe) and (iii) a recessionary period with substantially negative growth rates (2008-09, driven by the global financial crisis). In this we use classic macro data (surveys and production), as well as alternative data from Google (Google search data, already divided into categories and subcategories). We compare methods in terms of nowcasting ability as measured by Root Mean Square Forecast Error (RMSFE). Our empirical analysis yields four salient facts.
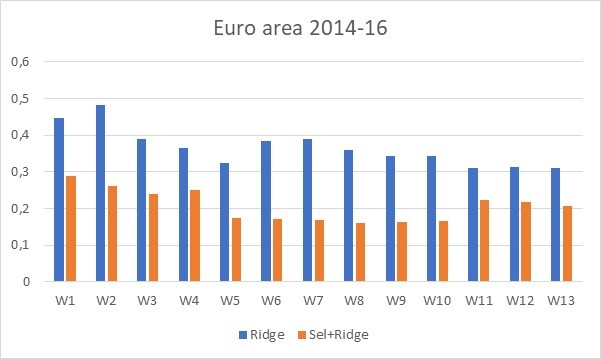
First, we combine the standard regression (using Ridge regularization) with the preselected regression (our Ridge after selection method). Figure 1 shows the results in the Eurozone during the calm period (2014-16). We clearly see gains in nowcasting accuracy for pre-selecting the data before entering the model. The idea is that having too many variables adds too much noise. This is especially true of Google search data, some of which are not directly related to economic activity.This result confirms previous results in the context of dynamic factor models (see Bai and Wu, 2008 or Barhoumi et al., 2009).
figure 1: The RMSFE for the euro area during the quiet period (2014-16) is derived from standard regression using Ridge regularization (blue bars) and Ridge after model selection (orange bars). Evolution of RMSFE over 13 weeks of the quarter. Source: Ferrara and Simeone (2023)
Second, we point to the usefulness of Google search data in forecasting GDP growth in the first four weeks of the quarter, that is, when there is no official information on the status of the current quarter. In Figure 1, we see that at the beginning of the quarter (from week 1 to week 4), the Google data does provide an accurate picture of the GDP growth rate, as the RMSFEs are rather low (between 0.2% and 0.3%), slightly This is higher than at the end of the quarter when all information was available (approximately 0.2%).
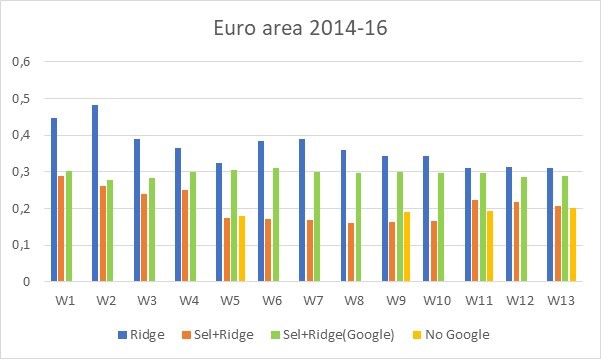
figure 2: RMSFE for the euro area during quiet periods (2014-16) from standard regression with Ridge regularization (blue bars), from Ridge after model selection method (orange bars), from model selection method using only Google data Ridge (green bars) and the base regression model without any Google data (yellow bars). Evolution of RMSFE over 13 weeks of current quarter Source: Ferrara and Simoni (2023)
Third, the relative nowcasting power of Google’s data fades quickly once official data becomes available, ie when the first polls for the quarter are released from week 5 (in the Eurozone case). We see in Figure 2 that for week 5, the RMSFE for all data (orange bars) is equivalent to the RMSFE without any Google data (yellow bars), that is. The first survey of the quarter contains only macro information. We also note that the RMSFE produced by Ridge after the model selection method using only Google data (green bars) does not show any drop over time, suggesting that the gain visible in the orange bars from week 5 onwards comes from the integration of macro variables.
Fourth, the decline period exhibits a specific pattern, as the model without any preselection and using only Google data as the information set provides the lowest RMSFE (green bars in Figure 3). This pattern is also generally seen in German and US data. This result must be further understood with more research, but it may be related to the well-known higher uncertainty we observe during recessions, which means more data must be used to explain it. In any case, this can be seen as a justification for using alternative data during a crisis.
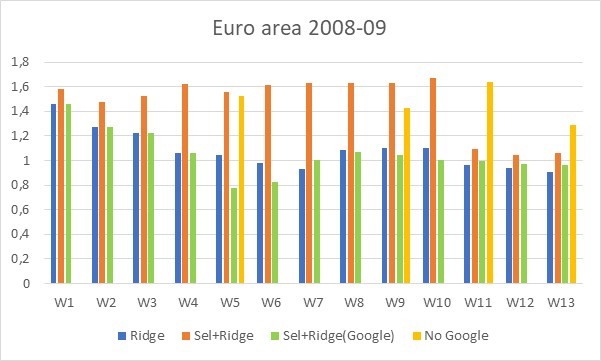
image 3: RMSFE for the euro area during recession (2008-09) from standard regression with Ridge regularization (blue bars), from Ridge’s method after model selection method (orange bars), from model selection method using only Google data Ridge after (green bars) and the basic regression model without any Google data (yellow bars). Evolution of RMSFE over 13 weeks of current quarter Source: Ferrara and Simoni (2023)
Various robustness checks confirm that these empirical results still hold for all countries in our analysis and remain valid when we augment the macroeconomic information set by considering 22 commonly used variables (sales, exports, employment, etc.). Finally, real-world analysis of the euro area and multi-year data corroborate the various methodological rankings. Overall, all these results suggest that after the preselection step, when information is scarce, Google data is very useful for forecasting GDP growth during the expansion phase. However, the marginal benefits of Google’s data tend to disappear quickly once official macroeconomic information arrives. During a recession, forecasters seem to need the largest set of information available to assess what is happening in economic activity.
This article was sponsored by Laurent Ferrara.


{kind=link}
{kind=link}