

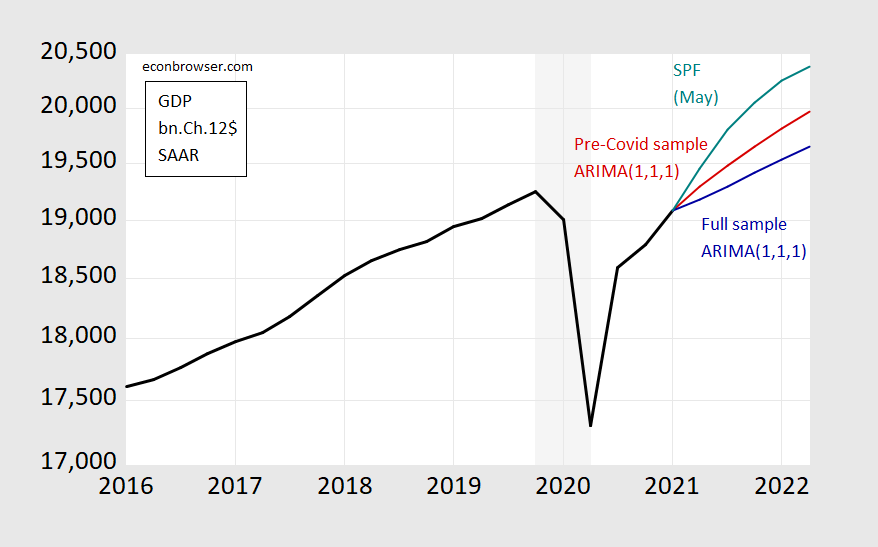
Consider the dilemma of a time-series econometric economist who hopes to make a quick and dirty forecast for next year, only conditioned on past GDP information. One person might get the series in the picture below.
figure 1: The reported GDP (black), the median forecast from the survey of professional forecasters (blue-green), the ARIMA(1,1,1) forecast using the data from 1986-2019Q4 (red), the ARIMA(1, 1,1) Forecast (blue-green), all with Ch.2012$SAAR as the unit. The light gray shading indicates the NBER recession date when the hypothetical trough is in the second quarter of 2020. Source: BEA, SPF, NBER and author’s calculations.
One’s initial tendency is to use all available information up to the latest data (first quarter of 2021) to estimate relationships and make predictions. This led to the blue line, where I used a simple time series model (ARIMA(1,1,1)), which traditionally does not work badly in a univariate environment. Alternatively, I can use the data available before the Covid-19 pandemic to estimate the relationship of interest. This led to the red line.
The actual forecasters surveyed by the Philadelphia Federal Reserve (blue-green) predicted that both were different-but presumably they were doing something different from the two. But in their case, they still have to face the question of what data to use (except for lagging output) and what restrictions are imposed on the model (Jim discusses these two issues) This post), what conditions are imposed (will the infrastructure plan be passed, will the new Covid-19 variant spread and how far?), what additional variables to use (such as big data, higher frequency data, etc.).
Paul Ho of the Federal Reserve Bank of Richmond In a more complex and comprehensive framework, some lessons learned from forecasting in unprecedented times are summarized.
How the forecaster adapts to the new environment
Faced with unique situations, forecasters must acknowledge the differences, and cannot completely ignore the lessons of the previous business cycle:
Should the COVID-19 pandemic be considered merely a period of high volatility?
Will changes in economic variables differ from previous recessions?
Will the impact of the pandemic spread and continue like other business cycle drivers?
These questions are important for forecasting, but due to the scarcity of available data, especially in the early stages of the pandemic, there are no accurate answers. As the pandemic spreads, how can forecasters solve such problems, acknowledge their level of confidence in the answers, and express how these problems affect their point forecasts and related uncertainties?In a recent working paper, “Prediction without precedent,” I discussed two broad ways to deal with the lack of precedent. First, forecasters use subjective judgment or prior knowledge-usually from economic theory-to adjust their models. This model adjustment is most effective when the basic assumptions of these models are transparent and the lack of certainty is acknowledged.
Or, forecasters usually find new sources of information by integrating new data into forecasting models. For example, epidemics and high-frequency data are of particular interest during a pandemic. However, predictors need to know how these new variables complement the variables of interest, which again raises the issue of model specification and hypothesis selection. This economic bulletin focuses on a few representative papers for each method.
Please note that forecasting and nowcasting are separate (albeit related) businesses.Regarding the latter, in the context of the Covid-19 recession, please refer to the Ecobrowser post Here with Here. Discussed some weekly indicators Here (OECD)Jim discusses the nowcasting methods of the Federal Reserve Bank of New York and the Federal Reserve Bank of Atlanta (before Covid-19) Here.


{kind=link}
{kind=link}